The SQL Server 2019 release includes new big data integration features, a collection of database engine enhancements and improved Linux and container support.
Following closely on the heels of its SQL Server 2016 and 2017 releases, Microsoft is already preparing to release SQL Server 2019, and the company has added a surprising number of new capabilities in a short time.
Enhanced big data integration is one of the major goals of the SQL Server 2019 release, which currently is available in preview mode. The new SQL Server big data clusters feature significantly broadens SQL Server's ability to query over data anywhere, providing better integration with big data systems over more supported platforms.
But that's not all. The SQL Server 2019 relational database engine has many enhancements that enable it to provide better performance and improved security. Microsoft has also continued to enhance SQL Server on Linux, bringing it closer to feature parity with SQL Server on Windows.
Let's dig into some of the most important new features in the upcoming SQL Server 2019 release.
Big data clusters enable data virtualization
SQL Server big data clusters enable deep integration with industry-standard big data sources, providing new data virtualization capabilities. SQL Server 2019 big data clusters utilize the capabilities of PolyBase to enable data virtualization, which combines data from many sources without moving or copying it.
Today's enterprise typically uses different types of data stored in a combination of relational and nonrelational data stores, and it usually needs to combine the data from both relational and big data sources. The highest-value enterprise data is stored in relational databases like SQL Server; that data often needs to be combined with big data sources, such as IoT data streams, which are primarily stored in Hadoop Distributed File System (HDFS). Organizations have typically used extract, transform and load (ETL) processes to copy data into a single platform where reporting and analysis are performed. This process is batch-oriented, is slow and requires large amounts of storage.
Using SQL Server's existing PolyBase technology, SQL Server 2019's big data clusters enable data virtualization that integrates data from multiple data sources without replicating or moving the data -- essentially combining high-value relational data with big data in a single query without the need to run any ETL process or use any extra storage. To enable this, the SQL Server 2019 database engine reads HDFS files natively.
Figure 1. The new features in these three areas are among the most anticipated ones in SQL Server 2019.
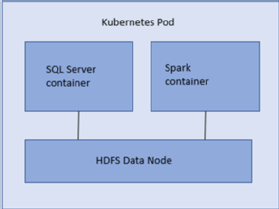
SQL Server 2019's big data clusters are built on a number of different technologies, including SQL Server on Linux in Docker containers, Apache Spark, Hadoop and Kubernetes. Big data clusters on SQL Server 2019 enable users to deploy scalable clusters of SQL Server containers on Kubernetes that can read, write and process big data using Transact-SQL.
A high-level overview of SQL Server 2019's big data clusters is shown in Figure 2. There, you see a big data cluster that consists of SQL Server and Spark Linux containers using Kubernetes for container management and orchestration. Queries are parallelized across multiple Docker containers running on a scalable group of nodes that comprise the compute tier. You can run advanced analytics and machine learning using Spark. Big data cluster activities are managed by a SQL Server master instance.
Figure 2. A high-level overview of SQL Server 2019's big data clusters.
Database engine enhancements
While the new big data clusters provide SQL Server 2019 with improved support for big data analytics, there's no doubt that the relational database engine is still the core of SQL Server 2019. Not surprisingly, the new release brings with it a number of new capabilities.
SQL Server 2019 has a database compatibility level of 150; compatibility level hints now dictate a query's exact compatibility level using the OPTION (USE) hint. In fact, lightweight query profiling infrastructure is enabled by default. New static data masking can sanitize sensitive data in copies of SQL Server databases. SQL Server 2019 also supports UTF-8 character encoding.
SQL Server 2019's new batch mode over row store capability enables queries to process data in batches instead of one row at a time; earlier releases limited batch mode to columnstore queries. Resumable online index creation enables an index creation operation to be paused and then later resumed from where it left off instead of having to restart.
Microsoft is preparing to release SQL Server 2019, and it has added a surprising number of new capabilities in a short time.
In earlier versions of SQL Server, creating a clustered columnstore index was an offline operation that required all changes to the underlying tables stop until the CCI was created; SQL Server 2019 enables users to create CCIs online. Support for compression estimates of columnstore indexes can be obtained using:
sp_estimate_data_compression_savings
A new APPROX_COUNT_DISTINCT function uses statistics instead of reading all of the data to get a count of distinct values in a column; the outcome is estimated to be within 2% of the actual value.
SQL Server 2019 also supports SQL Server Machine Learning Services failover clusters. Always Encrypted with secure enclaves enables SQL Server 2019 to perform in-place encryption and decryption actions without shifting the data out of the server. This enables data that is encrypted using Always Encrypted to be used in range scans, LIKE queries and aggregate functions. An enclave appears as a black box to the process that is calling it. Even though the data in the enclave is decrypted, its values cannot be seen by the calling process.
Always On Availability Groups with Kubernetes
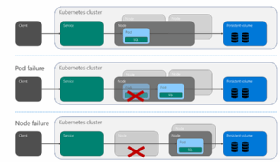
SQL Server 2019 also includes several significant improvements to Always On Availability Groups (AGs). The biggest change is the ability to configure Always On AGs using Kubernetes as an orchestration layer in place of Windows failover clustering. Kubernetes can be used to create an AG group consisting of SQL Server 2019 on Docker containers that works like a shared disk Windows failover cluster instance. Technically, this not a new capability, but SQL Server 2019 enables enhanced instance health check monitoring using the same operator pattern as AG health checks. An overview of SQL Server AGs on Kubernetes is shown in Figure 3.
Figure 3. A SQL Server Always On Availability Group on Kubernetes.
Kubernetes clusters consist of a master node that is used for management and worker nodes that run pods. Each pod can have one or more related containers. A SQL Server AG can span multiple nodes and can provide automated failover for both node and pod failure.
Always On AGs now support up to five synchronous replicas, an increase from the previous limit of three in SQL Server 2017. Synchronous replicas support automatic failover within the AG. In an AG with five synchronous replicas, there is one primary replica and four synchronous secondary replicas. Additionally, a new secondary-to-primary replica connection redirection capability enables client connections to be directed to the primary replica, regardless of the target server specified in the connection string without a listener.
SQL Server on Linux and Docker container enhancements
Since its initial introduction with SQL Server 2017, Microsoft has continued to bring SQL Server on Linux into closer parity with SQL Server on Windows. Some of the newest enhancements with the SQL Server 2019 release include support for transactional replication and distributed transactions.
SQL Server 2019 on Linux instances can participate in transactional, merge and snapshot replication topologies as a publisher, distributor or subscriber. Support for Microsoft Distributed Transaction Coordinator (MSDTC) enables SQL Server on Linux instances to conduct distributed transactions. To enable this capability, Microsoft created a Linux version of MSDTC that runs within the SQL Server process.
SQL Server 2019 provides improved integration between SQL Server on Linux and Active Directory (AD). SQL Server on Linux instances can use AD to authenticate users, as well as for replication, distributed queries and AGs. Additionally, the Linux version of SQL Server 2019 includes OpenLDAP support for third-party AD providers. SQL Server 2019 on Linux also provides new support for in-database machine learning.
Container support for SQL Server 2019 also has a couple of notable improvements. One is a new Red Hat Enterprise Linux (RHEL)-certified Docker container image:
Microsoft has also created a new master container registry. This is intended to be the official container registry for the distribution of Microsoft product containers. Microsoft Container Registry does not have its own catalog and is meant to support existing catalogs, like Docker Hub, Red Hat Container Catalog and Azure Marketplace. To download images from the new location, use a command like the following Docker pull command:
docker pull mcr.microsoft.com/mssql/server
SQL Server 2019 management tools
Like the previous versions of SQL Server, SQL Server Management Studio, SQL Server Data Tools and Azure Data Studio are the primary management and development tools for SQL Server 2019. All of these tools are free downloads that are available separately from the main SQL Server 2019 release. They are developed and made available on a separate and more frequent release cycle than SQL Server.
The new Azure Data Studio, which was known as SQL Operations Studio before Microsoft made it generally available in September 2018, is shown in Figure 4.
Figure 4. Azure Data Studio.
Next Steps
Learn how to best design SQL Server databases for effective performance